

Een stop aan het bandwerk in onderzoek?!
Kan Machine Learning het manuele codeerwerk reduceren?
(tekst Sven De Maeyer)
Alle onderzoekers, spits de oren. Wat je te lezen krijgt heeft de potentie om het saaie bandwerk van uren en dagen manueel coderen definitief achter je te laten. Het is allicht herkenbaar. Als we veel data willen dan houden we het vooral zo gestructureerd en gesloten mogelijk. Bij surveys stellen we het liefst (om het haalbaar te houden) geen open vragen aan de respondenten. En interviews beperk je ook tot een haalbaar aantal. Want hoeveel tijd gaat dat straks niet kosten om dat allemaal manueel te verwerken?
Hmm, “manueel” … is dat een woord dat nog hoort in deze tijd van Artificiële Intelligentie, Machine Learning, Deep Learning, Data mining, tekst mining, … en alle andere termen die we vanuit de computerwetenschappen naar het hoofd geslingerd krijgen? We deden de proef op de som en onderzochten de potentie van Machine Learning. De resultaten zijn alvast hoopgevend.
Een casus
Om dit te onderzoeken dook ik wat dieper in het materiaal uit het d-pac project (www.d-pac.be) wat zich buigt over de sterktes en zwaktes van Paarsgewijs Vergelijken als beoordelingsmethode. Eén van de onderzoekers (Marije Lesterhuis) heeft zich – vanuit de bezorgdheid rond validiteit – geworpen op de vraag:
“Welke aspecten nemen beoordelaars mee in hun beslissing als ze dienen aan te geven dat tekst A beter is dan tekst B?”
Om hierop een antwoord te kunnen formuleren vroeg ze aan 64 beoordelaars om samen bijna 2600 vergelijkingen te maken van teksten geschreven door 135 leerlingen uit het 5de jaar aso. De leerlingen schreven argumentatieve teksten waarin ze een onderbouwde opinie formuleerden over een onderwerp.
Beoordelaars kregen een set van willekeurig samengestelde paren van teksten voorgeschoteld en dienden 2 vragen te beantwoorden:
- Welke tekst vind je beter?
- Licht kort je keuze toe.
De tweede vraag resulteerde in wat we ‘decision statements’ noemen, een onderbouwing van de beoordelaars waarom ze de ene tekst beter vinden dan de andere. Dit is de input die Marije hanteerde om een antwoord te krijgen op haar onderzoeksvraag. Ze ging aan de slag met deze 2600 decision statements en codeerde deze (samen met collega’s) o.a. op 7 aspecten van tekstkwaliteit: argumentatie, organisatie, taalgebruik, taalconventies, referenties, brongebruik en layout.
Een voorbeeldje van zo’n decision statement:
“Ondanks de kleine schrijffouten zag de tekst er 1. Mooier qua structuur uit en 2. Werd er naar mijn mening meer argumentatie gebruikt. Men sprak over persoonlijke en economische motieven en verwees naar belangrijke bronnen. Dit ontbrak nogal in de rechtertekst.”
Ik hoor je al denken, waar zit nu de Machine Learning? Wel, de vraag die ik had, luidde: kan de computer straks een decision statement automatisch coderen en zo bv. vaststellen dat de beoordelaar verwijst naar taalconventies ?
Het antwoord is ronduit positief! Een tabelletje om dit te onderbouwen met daarin de vergelijking tussen ‘mens’ en ‘machine’. Hoe goed kan de computer de beoordelingen van Marije evenaren?
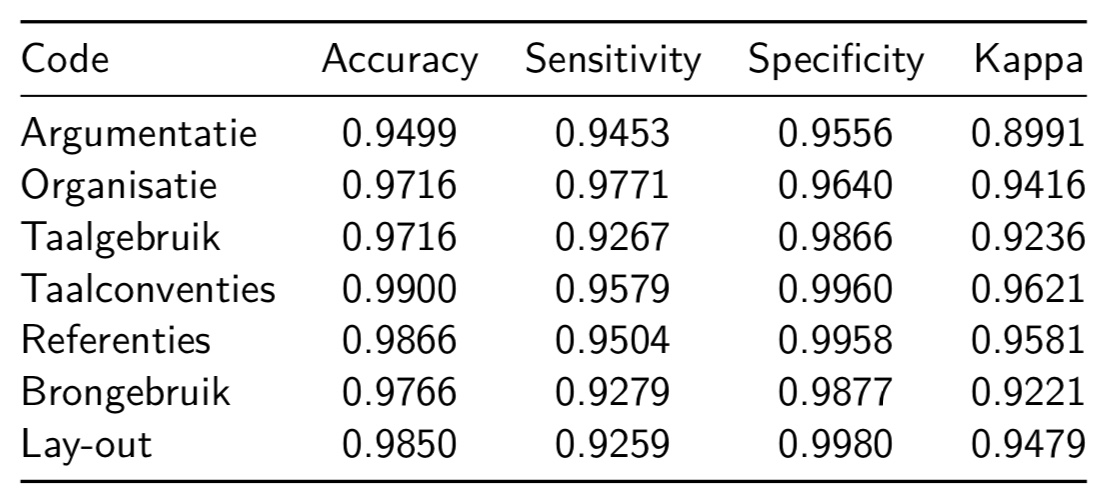
Een hele hoop cijfers! Maar, als je weet dat zowel Accuracy, Sensitivity en Specificity de overeenkomst uitdrukken in proporties (0 = 0% overeenkomst en 1=100% overeenkomst) tussen de computer en Marije, dan begint het misschien al door te dringen. Dit is positief nieuws. Kijken we bv. naar de code “taalconventies” dan leren we dat het algoritme 99% van de decision statements correct codeert. Een sensitiviteit van 95,8% leert ons dat het algoritme bijna alle decision statements die Marije codeerde als ‘taalconventies’ gelijkaardig codeert. En, een Kappa van 0,96 is een cijfer waar je nooit geraakt als je meerdere mensen aan het coderen zet.
Wat betekent dit nu?
Conclusie van het verhaal: de computer maakt straks zeer weinig fouten als er nieuwe decision statements gecodeerd moeten worden!
Dit opent uiteraard perspectieven. Zo kan Marije deze coderingen in het vervolg aan de computer overlaten. Of stel je voor dat je d-pac hanteert om studenten zelf inzicht te geven in hun ideeën over wat een goede tekst is. Dan kan je nu geheel automatisch studenten hun decision statements ontrafelen en feedback geven aan studenten. Hoe krachtig is het niet dat je een student straks kan teruggeven:
“Jij let blijkbaar zelf veel op taalconventies (schrijffouten etc.) en zelden of nooit heb je oog voor de structuur van een tekst. Bekijk een volgende set van teksten eens meer vanuit dit oogpunt.”
Uiteraard gaat dit geheel niet zonder risico’s. Eén van de belangrijkste risico’s blijft:
“Rubish in = Rubish out”.
Heb je als onderzoeker slecht gecodeerd dan gaat de machine vooral goed zijn in het na-apen van jouw slecht codeerwerk. Kwaliteitscontrole van de input voor zo’n Machine Learning algoritme blijft van groot belang.
Machine Learning heeft duidelijk veel potentieel voor onderzoekers. We hebben maar een tipje van de ijsberg aan mogelijkheden gezien. Stel je maar eens voor wat er nog allemaal mogelijk is. Als dit goed werkt zet dit de deur open naar grotere kwalitatieve dataverzamelingen en een uitgebreider gebruik van open velden in surveys. Immers, je zou ervoor kunnen opteren om als onderzoeker slechts een subset manueel te coderen als input om de computer te trainen. Nadien heb je dankzij de computer een grote set van gecodeerde data. Het zet ook de deur open naar grootschaligere documentanalyses (bv. het systematisch coderen van de rijkdom aan inspectieverslagen – ik zeg maar wat).
In een korte brainstorm binnen het EduBROn-team zagen we alvast veel potentie en uitdagingen. Heb je zin om samen met ons deze veel belovende piste verder te verkennen en mee op ontdekkingsreis te gaan, dan vind je in mij alvast een gepassioneerd reisgezel. Aarzel niet om nieuwe ideeën te posten of contact op te nemen.






1 Comment
Bram
about 7 jaar agoIn onderstaande podcast gaat men dieper in op hoe bias in (artificiële intelligentie) algoritmes sluipt. Daarom dat ik het argument om waakzaam te zijn heel belangrijk acht. Want soms denkt men dat technologie objectief en neutraal is, terwijl het tegendeel waar is, omdat het gedrag aanleert van faalbare mensen. Boeiend artikel en fascinerend hoe accuraat de voorspellinghen zijn. De tekstanalyse deed me wat denken aan de Yoast SEO plug-in, die blog-artikels kan screenen op leesbaarheid en kwaliteit ipv Google. Straf dat dat nu ook voor onderwijsdoelen kan. https://youarenotsosmart.com/2017/11/20/yanss-115-how-we-transferred-our-biases-into-our-machines-and-what-we-can-do-about-it/
Beantwoorden